Hadoop安装和配置


整体上Hadoop的安装和配置比较简单,因为通常需要分布式部署,所以要在多台服务器上安装和配置,还要顾及多台服务器之间的协作,所以会显得复杂。但是,只要理清原理和逻辑,就比较容易。
安装和部署主要有几点需要理解:
- Hadoop以及其他相关组件,都没有“安装”的过程,都只是把需要的文件放在服务器的某个地方。
- Hadoop的配置有两个主要的方面,一个是路径,就是让系统找到需要找到的可执行文件;二是配置文件,都是XML格式,目的是让Hadoop自己知道自己应该怎么运行。
- 分布式部署的时候,绝大多数的文件和配置都一样,所以可以直接克隆或拷贝。
前提
- JDK。因为Hadoop依赖于Java,所以需要提前安装好JDK,这里不细说,大家可以各自搜索。有些系统版本里可能直接就有了JDK。
- CentOS。下面的安装部署步骤是基于CentOS系统,我用的是虚拟机,如果本机就是CentOS且不准备进一步做分布式部署,也可以直接在本机安装(但不建议)。如果没有CentOS但是有其他的Linux发行版本,比如Ubuntu,也可以,只是某些具体的命令稍微不同。
- wget。用来下载安装包。但只要可以从某个网络地址下载包,是不是wget没关系。
- tar。用来解压安装包。
- vi。用来编辑文本的配置文件,其它文本编辑器也可以。
- 系统账户。正式的部署中通常会为Hadoop单独建立账号,而且会针对不同的服务创建不同的账户,但我的环境中并没有这么做,因为这属于常规的账号和权限管理的问题,对于Hadoop本身的安装部署并无区别。我的环境中的账号就叫“admin”。
下面一步步开始安装部署。
准备Hadoop目录
Hadoop不需要像普通应用一样的安装过程,但需要将其放在一个特定的目录中,我们需要规划好把它放在哪里。比如我把Hadoop放在如下位置:
![]()
![]()
这个位置随意,只要是当前账号可以访问的位置就可以。我们为了下面表述的方便,给这个位置起个名字,叫做<Hadoop根>,所有使用到这个名字的命令,都可以使用你真实的目录来替代。
但因为我的这个目录是”/home/admin/hadoop”,所以命令的回显会如是显示,请做相应理解。
这里我们确定好目录后,并不需要提前创建此目录,因为后面Hadoop的包加压后就是一个目录,我们可以将它重命名。
下载Hadoop包
使用如下命令,或相应功能的命令下载Hadoop包:
![]()
![]()
另外,我在下载前cd到当前账户的根目录,这样会使得hadoop包被下载到账户根目录。这个不是必须的,不管下载到哪里,解压后这个包就不再有用,可以删除,所以请自行确定将包下载到哪里。
然后用如下命令解压压缩包到它所在的目录,并将其移动到前面所定义的hadoop根目录(压缩包的版本号请以实际为准):
![]()
![]()
路径设置
现在我们有了解压后的hadoop目录,这是运行hadoop所需要的完整内容,里面包括可执行文件和配置文件,以及所有必须的文件。接下来只要让系统可以找到相应的目录和文件即可。
通过如下命令,使用vi编辑器编辑环境配置文件(或使用任何合适的文本编辑器):
![]()
![]()
并在文件最后(或任何你喜欢的位置),添加如下路径:

Hadoop路径设置
其中:
- HADOOPHOME、HADOOP_MAPRED_HOME、HADOOPCOMMON_HOME、HADOOPHDFS_HOME和YARN_HOME都指向<Hadoop根>。
- HADOOP_CONF_DIR指向Hadoop的配置目录,3.x版本中的配置目录如上图中配置所示,但其他版本可能有变化,请做适当调整。想知道这个目录应该指向哪里,可以在<Hadoop根>中搜索下面会用到的那些配置文件。
- 最后在PATH中添加Hadoop的bin目录,使用系统可以找到相应的可执行文件。
另外,如果尚未设置JAVA_HOME可以在此文件中添加:
![]()
![]()
其中:
- JAVA_HOME指向JDK安装目录中的jre目录。你的JAVA版本可能不一样,所在位置也可能不一样,请按实际情况设置。
- 最后在PATH中添加JAVA相应的bin目录,使系统可以找到相应的可执行文件。
在做完下面的路径设置之后,可以通过如下命令使其生效:
source ~/.bashrc 之后可以在终端通过下面的命令检查:java -version此命令用来打印所安装的java版本,应该得到如下结果:
![]()
![]()
java -version
再用如下命令检查hadoop:
hadoop version此命令用来打印hadoop的版本,应该得到如下结果:

配置Hadoop
至此,我们可以知道,hadoop已经正常“安装”,系统可以找到相应的文件。接下来通过修改配置文件,对其进行配置。
所有的配置文件都是文本文件,可以使用vi编辑器或任何文本编辑器进行编辑。
配置主要有四个文件:
- core-site.xml:hadoop全局的配置。

core-site.xml配置
这里的bd1.sos是我的服务器名,需要根据实际情况调整。
- hdfs-site.xml:HDFS相关的配置。
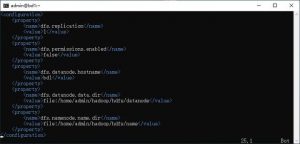
这里的dfs.datanode.data.dir和dfs.namenode.name.dir是我希望将我的环境中namenode和datanode的数据所存储的位置,可以根据实际情况调整。
- mapred-site.xml:MapReduce相关的配置。
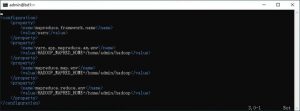
mapred-site.xml配置
其中三个路径需要根据实际情况调整。
- yarn-site.xml:Yarn相关的配置。
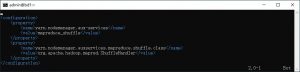
yarn-site.xml配置
所有的XML配置文件都使用统一的格式,其中的每一个property节点对应一个配置,一个文件里可以有多个配置。每个配置中使用name和value两个子节点保存配置名和值。每个文件里都可以有哪些设置可以查看hadoop官方文档,如下图左下显示的配置文件:
hadoop官方网站中的配置文件说明
另外,还有一个Hadoop_env.sh文件(以及一些其他配置文件),其中有详细的说明,目前我们的环境中不需要修改,但看一遍说明还是有好处的。
格式化HDFS
新安装的hadoop环境需要格式化HDFS,使用如下命令:
hdfs namenode -format应该得到如下结果:
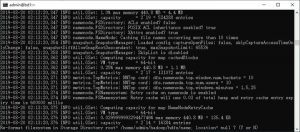
格式化NameNode
命令提示是否要格式化,输入Y回车。会得到:
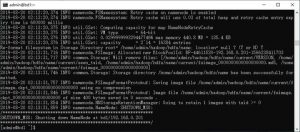
格式化NameNode
启动和停止Hadoop
如下命令,可以启动整个Hadoop系统,这一个shell脚本中包含了启动所有组件的命令,大家可以自动打开查看。在实际的部署中,通常不会通过这个命令来启动hadoop,而是根据需要在不同的服务器上执行不同的子命令来启动单独的某些服务,比如hdfs,yarn等。
~/hadoop/sbin/start-all.sh此命令应该得到如下结果,说明hadoop已经成功启动:
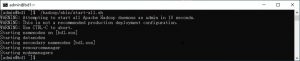
~/hadoop/sbin/stop-all.sh应该得到如下结果,说明hadoop已经停止:

查看HDFS中的文件
我们可以通过如下命令,列出HDFS中的文件,进一步确认hadoop已经正常工作:
hdfs dfs -ls /此命令应该得到如下结果(因为HDFS中没有任何文件,所以是空的,但不应报错):
网页
- 浏览器打bd1.sos:9870,其中bd1.sos是我的服务器的名字,请根据实际情况调整。
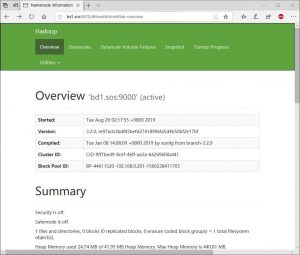
HDFS的网页界面
注意:
- 不同版本的hadoop的端口不同,比如上面的9870在Hadoop 2.x中是50070,需要注意。

